Przed świętami dostałem wiadomość od Sadiego z paroma pytaniami o podstawowych aspektach obróbki głosu. Wysłałem mu parę notatek, ale wydaje mi się, ze skoro mam taką możliwość to wrzucę tutaj troszkę informacji o obróbce wokalu. Postaram się zdemaskować parę naprawdę ważnych mitów związanych z kompresją, limitacją i rożnymi efektami, które zainteresowani na pewno już znają, ale chcieliby wiedzieć o nich trochę więcej.
Oczywiście z chęcią odpowiem na rożne pytania i podesłane mi obrobione nagranie z jakimiś konkretnymi złośliwostkami dotyczącymi postprodukcji.
Kompresja
Jednym z najważniejszych elementów w miksowaniu jest kompresja. Niezmiernie ważne żeby zrozumieć o co w niej chodzi. Strasznie łatwo rozpoznać czy dane nagranie przeszło czy nie przeszło przez poprawną kompresję. W świecie audio używamy kompresorów, aby wyrównać dynamikę ścieżek dźwiękowych (Czyli sprawić, że głośniejsze stanie się cichsze, a cichsze głośniejsze). W przypadku wokalu może się zdarzyć ze będziemy mieli bardzo gorący sygnał gdzie wokalista krzyczy do mikrofonu, a chwile później szepcze. Jeżeli z jakiegoś powodu nie będziemy chcieli nagrać tych dwóch miejsc oddzielnie to kompresor może nam pomóc wyrównać głośność tego sygnału. W tym wypadku pewnie będziemy chcieli stworzyć blokadę (threshold) w miejscu gdzie uważamy, że kompresja powinna się zaczynać. A co to threshold? Możemy kręcić każdym pokrętełkiem na kompresorze, ale jeżeli threshold jest wyższy niż sam wejściowy sygnał który ma przechodzić przez kompresje to nic się nie stanie. Można na to spojrzeć w ten sposób. Jeżeli mamy turbinę wodną wiszącą 3 metry nad poziomem wody to oczywiście nie będzie pracowała, prawda? Kiedy obniżymy turbinę to zacznie pracować. Z podobnym nastawieniem możemy podchodzić do ustawiania thresholdu.
Ponadto na kompresorach mamy parę innych możliwości edytowania sygnału. Zetkniemy się z opcjami: threshold*, ratio, attack, release i make up gain.
Co robi każdy z tych elementów oznacza łatwo można wytłumaczyć używając obrazka poniżej.
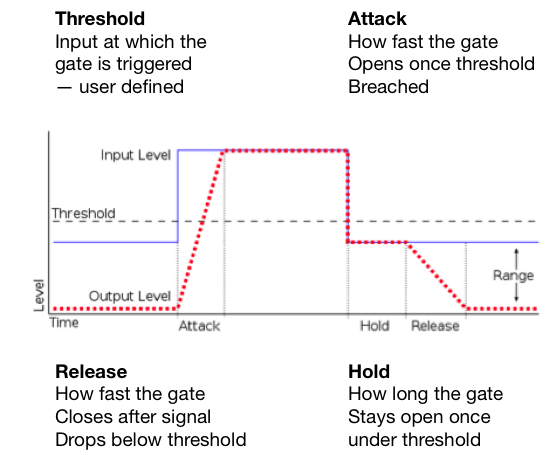
Fig 1 Co tak naprawdę dzieje się z wejściowym sygnałem podczas kompresji.
Threshold pozwala na kontrolę kiedy kompresor zaczyna działać. Prawdopodobnie najważniejszy element wymagający poprawnego ustawienia. Jeżeli threshold jest za łagodny (bliższy -0dB) to żadna kompresja nie będzie miała miejsca. (dB = decybel)
Attack to ilość czasu, który kompresor bierze zanim zacznie działać. Mówimy o małych jednostkach czyli 1ms – 2000ms.
Release to ilość czasu, który kompresor bierze zanim przestanie oddziaływać na sygnał. To może brzmieć jak dziwna opcja, ale release pozwala na wiele naprawdę fajnych brzmień kiedy zrozumie się o co w nim chodzi. Dla zainteresowanych* przez ustawianie bardzo krótkiego release time na perkusji możemy sprawić, że będzie brzmieć bardziej agresywnie i jaśniej bez dodawania żadnego EQ. Używając release time możemy dodawać zawartość harmoniczną do rożnych nagrań przez przesterowanie niskich częstotliwości.
Make-up-gain W rzeczywistości kompresor nie robi nic oprócz obcinania szczytowego sygnału (peak signal) przechodzącego przez threshold. Przez to wszystkie głośne dźwięki na ścieżce będą cichsze. Ustawienie thresholdu sprawia ze poziomy głośności będą bardziej zgodne. W takim razie po obcięciu głośnych dźwięków możemy użyć make-up-gain żeby podnieść sygnał z powrotem do naszego wymarzonego poziomu.
Trzeba oczywiście pamiętać, że kompresja działa również na hałas tła nagrania! Za każdy 1dB redukcji sygnału hałas tła w cichszych miejscach podniesie się o 1dB. Dodatkowo musimy pamiętać ze ciężka kompresja może również wyolbrzymiać spółgłoski szczelinowe: s, sz, cz, ś, ź…
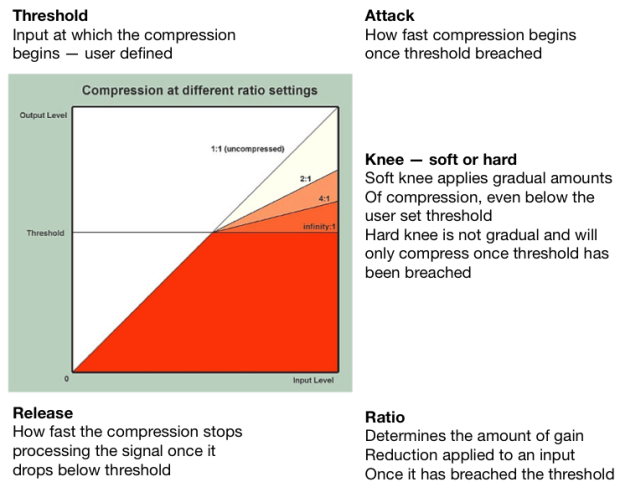
Fig 2 Tak będzie wyglądało okienko kompresora z graficznym wyświetlaczem. Ważne żeby zrozumieć co robi ratio.
Z podstawową wiedzą warto od razu przystąpić do testowania tego wszystkiego przez kręcenie pokrętełkami samemu. Tak można wprowadzić w życie trochę teorii i wyrobić sobie własne zdanie o brzmieniach produkowanych przez rożne kompresory.
Ratio kontroluje intensywność kompresji po przejściu przez threshold. Na przykład:
*Kompresja 2:1 oznacza, że za każde 2dB które przechodzą przez threshold, tylko 1dB tego sygnału tak naprawdę wyjdzie na zewnątrz. Dlatego ratio 4:1 oznacza, że będzie trzeba upchnąć 8dB przez threshold żeby wydobyć z niego sygnał 2dB. Ratio 8:1 oznacza, że będzie trzeba upchnąć 16dB przez threshold żeby wydobyć z niego sygnał 2dB. Więcej kompresji mniej wychodzącego sygnału, ale też kompresor bardziej koloruje sygnał. Każdy kompresor ma swoje własne brzmienie!
PRESETS
No dobra, ale jak to się ma do nagrań z którymi możemy się spotkać. Zanim ktoś zrozumie na czym polega ten cały koncept z kompresją pewnie będzie chciał mieć parę miejsc, od których będzie mógł zacząć.
‘PRESETS’ (ustawienia) które teraz podam powinny być dobrym punktem startowym! Dobrze mieć swoje miejsca gdzie się zaczyna, ale każdy głos jest inny zatem potrzebuje innej edycji. Każdy musi mieć własne zdanie. To że ktoś używa jakieś ustawienia na swoich nagraniach nie znaczy, że te same ustawienia będą działały na twoich. W świecie audio po prostu tak jest. Nie ma jednego złotego środku na to wymarzone, wspaniałe brzmienie.
Wokal
Attack: 10 – 50ms
Release: 200 – 2000ms (Zazwyczaj ustawiam szybszy release czas, ale wszystko zależy od tego jaki efekt chcę uzyskać)
Ratio: 2:1 – 4:1 (łagodne)
Threshold: często będę ustawiał tak żeby było 12dB redukcji w najgłośniejszych miejscach piosenki
Make-up-gain: to wasz problem. Sami go rozkminiajcie.
No dobra przejdźmy teraz na chwile do limiterów. Czym jest limiter? Limiter jest kompresorem z wysokim ratio i zazwyczaj szybkim attack time. Dla mnie kompresor z ratio 10:1 lub więcej to limiter. Odważę się nawet powiedzieć, że limiter znajduje się na prawie każdym stereo busie piosenek w dzisiejszej branży muzycznej. Używanie limiterów związane jest z całkiem nieprzyjemnym brzmieniem przesterowanego sygnału w domenie cyfrowej, który kompletnie niszczy muzykę w cyfrowym formacie. Niektórzy zachwycają się przesterami na płytach winylowych, ale jakoś nie znam nikogo kto dla relaksu słucha przesterowanych sygnałów domeny cyfrowej ;]
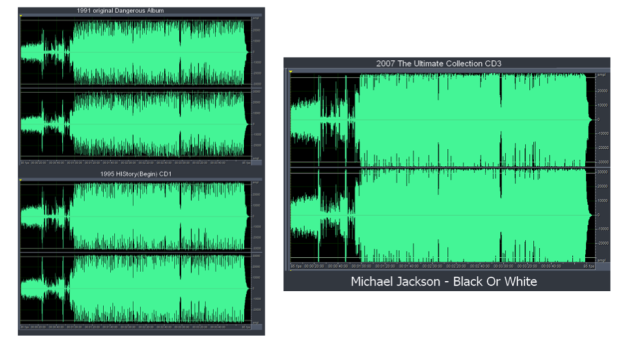
Fig 3 Miksy „Black Or White” MJ’a. Ciekawy przykład z widoczną kompresją i zmianą w dynamice piosenki po remiksach w 1995 i 2007. Jeżeli ciekawi was Wojna Głośności „The Loudness War” to tutaj jest krótki filmik, który jasno pokazuje jak jakość dźwięku cierpi po nadmiernym limitowaniu sygnału.
Limiter
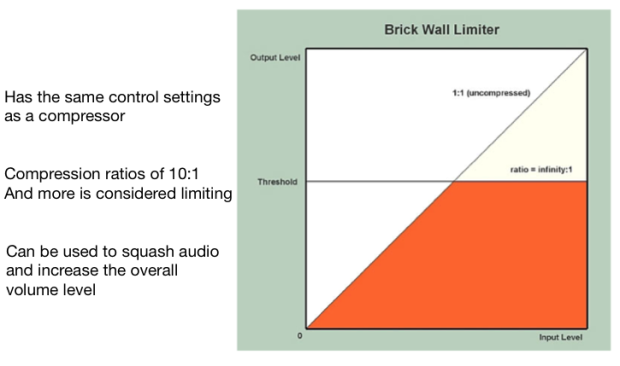
Fig 4. Limiter inaczej Brick Wall Limiter.
Teraz kiedy już wiemy co robią kompresor i limiter zabierzmy się za kolejny fundamentalny askpekt miksowania. Jeżeli kiedykolwiek miksowałeś/aś to wiesz jak trudno jest poskromić dynamikę wszystkich dostępnych nagrań i sprawić żeby w przyjemny sposób skleiły się w jakąś całość. Jest to trudne w szczególności jeżeli jeszcze nie zniszczyliśmy krzywej uczenia(learning curve) i nadal nie jesteśmy pewni jak działają narzędzia których używamy. Przejdźmy w takim razie do bardzo szybkiej zasady miksowania, która powinna przyświecać nam za każdym razem kiedy siadamy do pracy nad jakimś nagraniem.
Generalnie nie chcemy żeby jakikolwiek sygnał wychodził poza -6 decibel full scale (dBFS) na naszym mierniku głośności. W zależności od tego z jakim gatunkiem muzycznym pracujemy możemy chcieć popchnąć tę granice do -3dBFS. Dobrym przykładem gdzie pewnie będziemy chcieli wyciągnąć wszystko jak najgłośniej jest miksowanie dzisiejszej muzyki popularnej. Poza tym, podczas miksowania spotkamy się często z kawałkami sygnału, które będą się wybijały poza nasz zdrowy limit -3 lub -6dBFS. Takim przykładem może być werbel, który ma się przebijać przez miks. Tak długo jak będziemy mieli ustawiony limiter na naszym stereo busie na np. -0.1dBFs nie powinniśmy się o nic martwic. Zakładając, że jesteśmy usatysfakcjonowani wszystkimi poziomami głośności to w procesie masteringu i tak mamy możliwość zmiażdżenia i wyrównania wybijających się sygnałów z resztą piosenki przy użyciu kolejnego limitera.
Ta ‘przestrzeń’ pomiędzy -6 a 0dBFS nazywana jest headroomem. Headroom pozwala nam na stworzenie finałowego masteru gdzie mamy pełną kontrole nad głośnością, którą z łatwością możemy podgłośnić przy pomocy kompresji i limitacji. W domenie cyfrowej nie da się podgłosnić miksu, który już jest przesterowany. Nie da się tego bardziej podkreślić. Powtórzę.
W domenie cyfrowej nie da się podgłośnić czegoś co już jest na granicy przesteru.
Potrzebujemy naszego miejsca, przestrzeni innymi słowy… Potrzebujemy headroomu.
Kiedy już przygotujemy nasz pierwszy miks z odpowiednia ilością headroomu wystarczy, że otworzymy sobie nowy projekt w naszym DAWie (Digital Working Station) i zaczniemy obróbkę naszego wyeksportowanego miksu. Eksportowany plik, który będziemy używać od produkcji finałowego masteru powinien być najlepszej jakosci. Najlepiej urzywać rozszerzeń .wav albo .aiff, są to bowiem pliki bezstratnej kompresji.
Podczas pracy nad finałowym masterem poprawiamy nasz miks na rozmaite sposoby. Tutaj napisze tylko o kompresji która jest ostatnim elementem który wpływa na nasz sygnał przed wyjściem głównym (main output).
Z naszym wychodzącym sygnałem będziemy chcieli zrobić dwie podstawowe rzeczy. Pierwsza to nałożenie lekkiej kompresji na naszym torze, która tylko pocałuje wybijające się części sygnału. W tym momencie chcemy bardzo subtelnie skleić cały sygnał z może 1dB lub 2dB redukcji. W ostatniej kolejności wrzucamy limiter, po czym ustawiamy threshold (tak jak chcemy) i ‘out ceiling’ (to ustawiamy na -0.1dBFS). Nasz ‘out ceiling’ zapobiega przedostawania się sygnałów w rejon przesterowania. Po ustawieniu thresholdu najlepiej sprawdzić najgłośniejsze miejsca naszego sygnału słuchając czy przypadkiem niczego nie przesterujemy.
Jeżeli już jesteśmy usatysfakcjonowani z naszym miksem klikamy eksport i maszerujemy posłuchać go na jakimś innym systemie niż ten którego używaliśmy do miksowania… Po kilku minutach siadamy i zaczynamy poprawiać błędy z których obecności nie zdawaliśmy sobie sprawy podczas miksowania na naszych głośnikach lub słuchawkach. Witamy w świecie realizatorów dźwięku…
Reverb
W obróbce głosu jednym z najważniejszych efektów jest kompresja. Naprawdę ważne żeby zrozumieć co robi z sygnałem. Kolejnym efektem jest reverb czyli pogłos (rewerberacja) – zjawisko stopniowego zanikania energii dźwięku po ucichnięciu źródła, związane z występowaniem dużej liczby fal odbitych od powierzchni pomieszczenia. Jest mnóstwo efektów gdzie to zjawisko jest sprytnie odwzorowane za pomocą całkiem skomplikowanych algorytmów. Reverb jest szczególnie ważny jeżeli wokalista/ka jest niepewny swojego głosu, albo po prostu kiepsko śpiewa. Odrobina pogłosu może dać naprawdę dużo, ale nie zdziała cudów. Kiepskie nagranie pozostanie nim niezależnie od tego ile pogłosu czy EQ do niego dołożymy. Ważne żeby o tym pamiętać.
Z efektami najlepiej pobawić się samemu i odkrywać własne brzmienia. Jakkolwiek cała zabawa zaczyna się w momencie kiedy próbujemy odwzorować jakiś efekt. Jak stworzyć reverb Elvisa na naszych nagraniach? Możemy użyć jakiś mały plate reverb albo emulator tape delay z mniej więcej 100-120ms predalay, 0 feedback, odrobiną EQ i będziemy mieli jakiś odpowiednik pogłosu z lat 50tych. Nie takie trudne. Gorzej kiedy nie mamy takiej informacji i nawet nie wiemy gdzie zacząć. W takich momentach musimy polegać na naszych uszach, ale również na naszej kreatywności. Zawsze możemy coś skopiować, ale dopiero to jak to odtworzymy zadecyduje o naszych umiejętnościach. Możemy odwrócić albo reampować cały proces, dodać jakiś dziwny efekt sprawić żeby brzmiało tak jak efekt stworzony przez Ciebie a nie kogoś innego.
To co próbuję powiedzieć to to ze każdy kto się interesuje tego typu procesem postprodukcji powinien sam poeksperymentować z możliwościami efektów które posiada bo w ten sposób najlepiej się ich nauczy.
No tak, ale łatwo coś takiego powiedzieć. Warto oczywiście wiedzieć co one tak naprawdę robią. Zazwyczaj ważniejsze jest to jak coś brzmi niż jak coś działa. W końcu większość ludzi będzie słuchało muzyki a nie czytało przez jaką postprodukcje przeszła poszczególna piosenka. Realizator dźwięku, producent, muzyk oni mogą być ciekawi, ale nie przeciętny słuchacz.
Co do efektów, które mogę polecić do obróbki głosu i nie tylko to warto zerknąć na: Izotope Alloy 2, TrueVerb Waves, L2 Ultramaximizer Waves
Maciek (Razjel)